Ciascuna realtà aziendale deve fronteggiare la sfida di amministrare correttamente l’enorme mole di dati che produce. Fatture, dati dei prodotti, clienti, bolle di spedizione sono solo una piccola parte delle informazioni che quotidianamente le nostre aziende si trovano a gestire. Per non parlare del GDPR e la valenza legale che i dati personali arrivano ad avere. Connettere sistemi, validare i dati, indirizzare parzialmente il dato è un lavoro complesso.
Probabilmente fino ad ora la tua azienda ha gestito il problema creando tanti canali di comunicazione che diventano sempre più difficili a da monitorare e manutenere. Per fortuna la fondazione Apache ha un prodotto per risolvere questi nostri problemi ed è Apache NIFI.
Apache NIFI è un applicativo Java di modellazione di flussi di dati (DFM – Data Flow Modelling) che permette di visualizzare, monitorare e modificare sistemi di integrazione e passaggio di dati.
- Di cosa tratterà e non tratterà questo articolo
- Le 4 grandi V dei sistemi di gestione di BigData
- Prospettiva a grandi linee del problema
- Apache NIFI, l’applicativo
- Consapevolezza dello stato dei flussi
- Quindi, quando conviene usare Apache NIFI?
Di cosa tratterà e non tratterà questo articolo
L’obiettivo di questo articolo è quello di darti una visione ad alto livello delle capacità di Apache NIFI, la sua interfaccia e le potenzialità. Scenderò quanto basta nel linguaggio tecnico sopratutto per introdurre concetti e sistemi. Non parlerà invece di problemi tecnici come l’installazione, la sicurezza, la configurazione, mantenendomi ad un livello più alto.
Le 4 grandi V dei sistemi di gestione di BigData
Facciamo un passo indietro, perché utilizzare un sistema che utilizza i dati? Quali sono le caratteristiche necessarie?
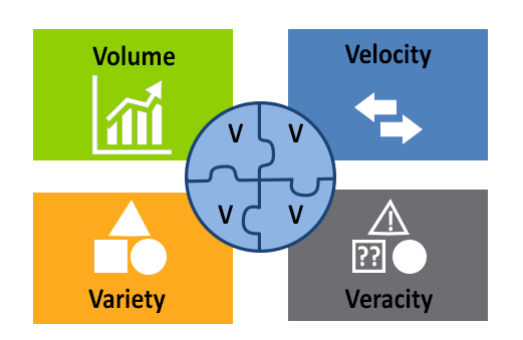
- Queste sono le 4V su cui devono essere pesati sistemi di gestione di grandi informazioni
- Volume: essere in grado di gestire grandi quantità di informazioni; Giga? Tera? Peta?
- Veracity: veridicità dell’informazione, ovvero la certezza che l’informazione non cambi nel suo significato durante i passaggi e le trasformazioni o anche quanto il dato deve essere ripulito prima di essere utilizzabile.
- Variety: tipologia di dati che un sistema può gestire (file, immagini, csv, db, etc..) e la frequenza con cui il dato varia nel tempo.
- Velocity: rapidità con la quale un’infomazione viene elaborata.
Apache NIFI, come emerge dai punti già affrontati, soddisfa molte di queste condizioni.
Prospettiva a grandi linee del problema
Semplificando il più possibile il problema abbiamo la seguente situazione:
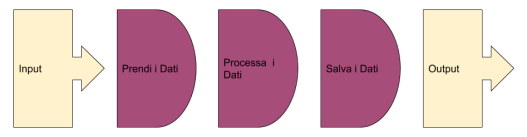
Dato un input e un output dobbiamo raggiungere i dati, elaborarli e poi restituirli all’output nel nuovo formato. Se volessimo implementare da zero questa integrazione dovremmo farlo con qualche centinaio di righe di codice. Su Apache NIFI invece questo comportamento si può simulare con una struttura di questo tipo.
Intuitivo
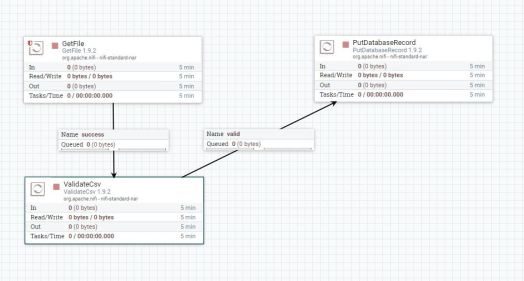
Oltre alla rapidità di creazione, Apache NIFI ci permette di visualizzare in modo espressivo il flusso fornendoci una comprensione e una malleabilità migliori.
Potente
Apache NIFI presenta all’interno innumerevoli connettori (FILE, DB, REST, WS) già implementati per ottenere e scrivere dati. A corredo ha un’ampia gamma di controller per la validazione e la manipolazione del dato. In questo modo la maggior parte del lavoro sarà trovare il controller giusto e quindi configurarlo appropriatamente.
NB: Non confondiamo APACHE NIFI con un ETL (Extract, Transform, Load) System. Le capacità di trasformazione e manipolazione non sono così potenti; quindi nel caso in cui serva una massiva trasformazione del dato è consigliabile sviluppare dei moduli dedicati, oppure integrare il flusso di dati un un ETL che si occuperà del lavoro.
Scalabile e stabile
L’infrastruttura logica su cui è stato edificato Apache NIFI si avvale delle migliori linee guida per quanto riguarda scalabilità e stabilità.
Il sistema si può avvalere di un cluster con numerose istanze per processare un numero superiore di dati. L’utilizzo della backpressure consente di non avere dei down causati da picchi di dati comunicati ma piuttosto di accodarli e processarli utilizzando al massimo le risorse
Rende più intuitiva la comprensione fra data analyst e gli altri
Il flusso di dati espresso tramite Apache NIFI è eccellente anche come documento per la comunicazione interna. Un non tecnico può agevolmente comprendere i passi all’interno di un flusso e il personale tecnico può confrontarsi con più efficacia su implementazioni o revisioni.
Dobbiamo quindi utilizzare Apache NIFI?
In base alle caratteristiche elencate è lampante che Apache NIFI sia un ottimo strumento per la gestione di flussi di dati. Nel caso in cui le integrazioni nella vostra infrastruttura siano già presenti numerose suggerirei di introdurre gradualmente Apache NIFI, in alcuni casi rimpiazzando la struttura in essere, in altri gestendo l’input e l’output come se fosse un processo esterno.
Apache NIFI, l’applicativo
Terminata la descrizione di massima entriamo più in dettaglio nel funzionamento dell’applicativo. Apache NIFI è un applicativo Web Based e l’interfaccia è accessibile da un qualsiasi browser.
Strutture principali
Come detto in precedenza lo schema base di connessione in Apache Nifi è molto semplice, introduciamo quindi i 4 interlocutori principali:
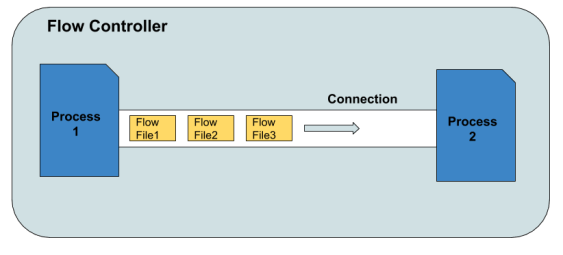
FlowFile
Il FlowFile è l’informazione minimale veicolata all’interno dell’applicativo. E’ composta da un contenuto (il corpo dell’informazione) e degli attributi chiave -> valore che vanno a definire e caratterizzare l’informazione. Tutti i FlowFile hanno di base uuid, filename e path.
Processor
Il Processor rappresenta l’azione. Ogni operazione di recepimento, trasformazione o organizzazione dei FlowFile è operata da un Processor. Apache Nifi fornisce di base numerosi Processor già implementati e configurabili. E’ possibile creare dei Processor custom in java per espandere le potenzialità di questo strumento.
Relationship
Ogni processo può avere zero o più relazioni orientate con altri processi. Queste relazioni trasportano i risultati di un processo verso un altro e sono definiti dall’esito dell’operazione, ad esempio:
- success
- fail
- retry
- …
Le relazione possono essere multiple per lo stesso output; quindi una trasformazione potrà essere inviata e salvata nel DB e allo stesso tempo scritta all’interno di un file di log. Le relazioni veicolano FlowFiles tramite delle Connection.
Connection
Le connessioni fra Process contengono una coda di FlowFiles inviati dal processo mittente e in attesa del processo emittente. Una Connection può veicolare più tipi di Relationship e può esistere una sola connessione fra 2 processi. La coda presente all’interno della connessione permette di gestire la stabilità interna del flusso: nel caso in cui un processo generi troppi dati, questi verranno smaltiti dal processo successivo senza sovraccaricare il sistema (Internal BackPressure).
Controller Service
Il Controller Service è il contesto in cui operano i Process, questo mette a disposizione configurazioni, connettori e altre informazioni a tutti i processi all’interno del flusso.
Process Group locali e remoti
Considerando la complessità di un flusso di informazioni e l’importanza di avere un’informazione chiara e visibile, Apache Nifi fornisce la possibilità di aggregare strutture di Process all’interno di Process Group. Sarà quindi possibile creare schemi di gruppi di processi che andranno a modellare trasformazioni complesse per poi poter vedere in dettaglio l’implementazione di ogni singolo passo. Apache Nifi è predisposto anche per la comunicazione ad istanze remote di Apache Nifi tramite connettori.
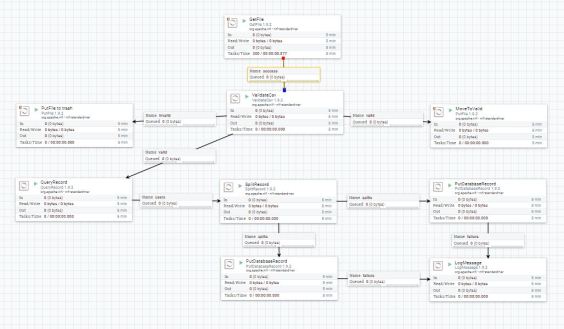
Consapevolezza dello stato dei flussi
Conosci lo stato del trasferimento dei tuoi flussi?
Quanti dati vengono passati in un giorno?
Apache Nifi fornisce delle metriche utili stimare tutti gli spostamenti all’interno dei Flusso di dati.
Statistiche in tempo reale
Direttamente dal Flusso visuale dei dati è possibile monitorare il numero di pacchetti passati negli ultimi 5 minuti, i pacchetti in coda e quelli processati sia a livello di numero che di dimensione. Questi dati permettono di capire lo stato istantaneo della piattaforma ed eventuali colli di bottiglia.
Affidabilità
Apache Nifi si avvale di FlowFile Repository e Provenance Repository per tenere traccia di tutte le informazioni riguardanti il FlowFile:
- FlowFile Repository mantiene l’ultimo stato di ogni FlowFile, questo permette di poter recuperare velocemente da un’interruzione del servizio software o hardware
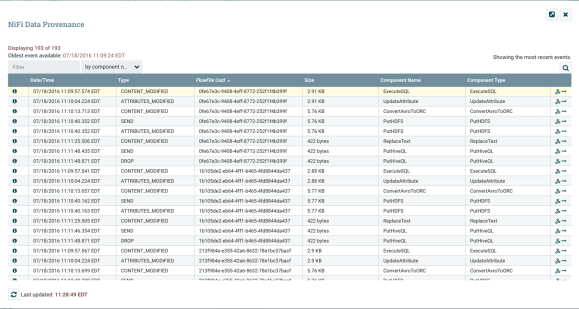
- Provenance Repository mantiene invece lo storico dei FlowFile permettendo di visualizzare ogni suo stato precedente. Questo è molto utile per indagare su trasformazioni impreviste o perdite di informazione.
La pagina di Data Provenance aggrega eventi e trasformazioni riguardanti i FlowFile.
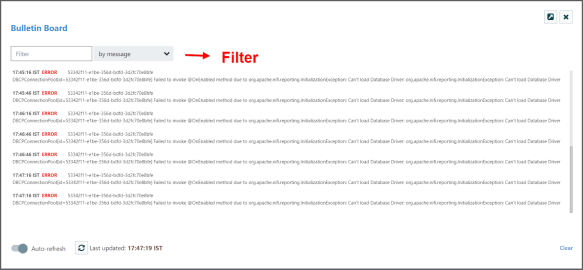
Bulletin Board
Oltre a monitorare statistiche e stato dei file, Apache Nifi possiede una Bulletin Board che raccoglie tutti gli errori verificatesi. Questi saranno visibili come dei postId all’interno del process dove si è verificato l’errore e raggruppati (sempre filtrabili) all’interno di una pagina ad hoc.
Quindi, quando conviene usare Apache NIFI?
Non esistono strumenti magici che fanno tutto, ma va ammesso che le potenzialità di Apache NIFI lo rendono un prodotto multisfaccettato. Ma la prima domanda che dobbiamo porci è: quando non usarlo?
Per piccoli sistemi o piccole integrazioni probabilmente Apache NIFI è eccessivo, a meno che non si usi su un cluster condiviso tra più clienti, così da fornire un costo del servizio più basso.
Mentre invece è eccellente per effettuare trasporti di informazioni tra vari sistemi, per lavorare sui BigData, e per importare dati.
E’ molto interessante anche perché, grazie alla gestione del carico, permette di non far collassare le varie risorse coinvolte. Utile quindi anche in casi di moli enormi di dati o di moli inaspettate. Noi l’abbiamo apprezzato per tutte questi dettagli e anche per l’interfaccia web che dona una visione completa dei sistemi e del loro stato, del carico e degli errori.
CONTATTACI PER AVERE MAGGIORI INFORMAZIONI